CTFshow-Web入门-信息搜集writeup

Web1
Hint: 开发注释未及时删除
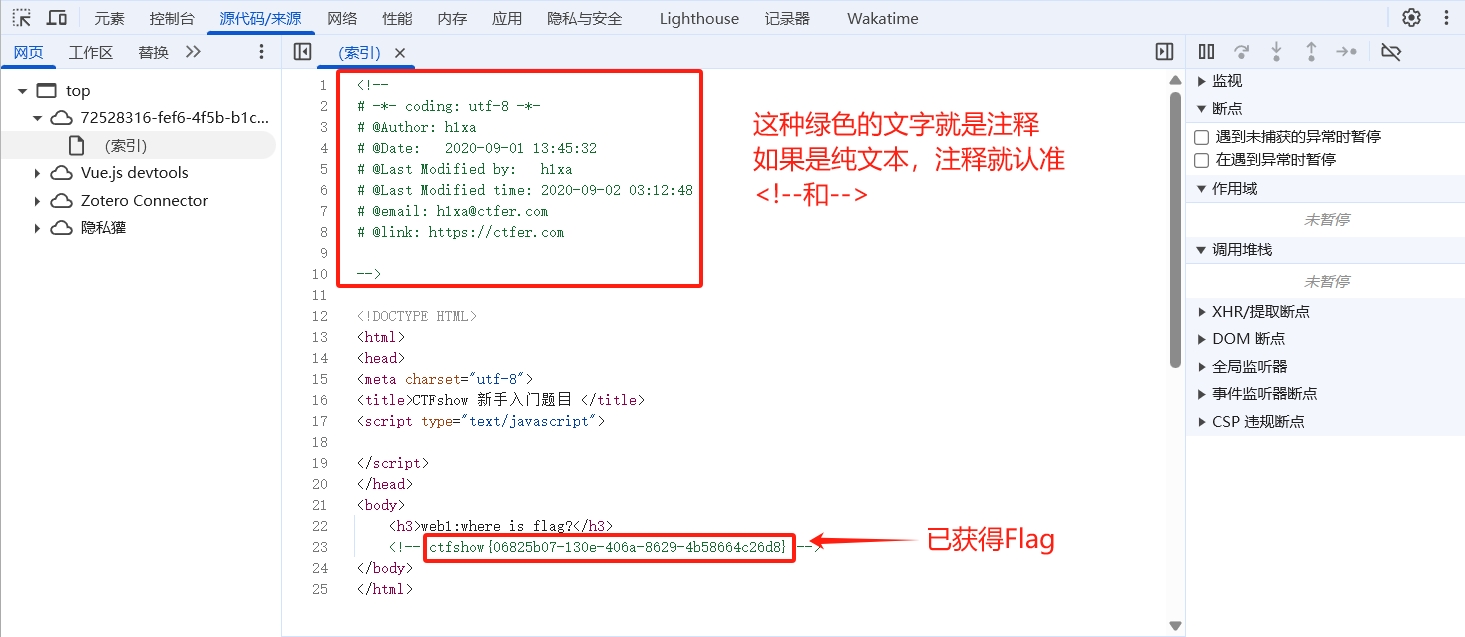
注意到开发注释未及时删除的提示,联想到查看网站的源代码,说明网站源代码中有猫腻。
于是在靶场网站页面按F12进入开发者控制台,果然于注释之中发现了Flag,本题结束。
为了保证不影响页面排布,我将开发者控制台设置为独立窗口显示。
Web2
Hint: js前台拦截 === 无效操作
这回打开靶机,发现上面写着无法查看源代码。按F12发现的确没有用,而且注意到网址中鼠标右击也已被禁用。
因此,我们有以下两种思路:化繁为简亦或变通
方案一:回归本源
无论是禁止F12或是禁止右键点击行为,本质上都只是禁用了现行较为方便的源代码查看方式。但是,源代码的查看方式被屏蔽不等于源代码就不存在了。
请注意,前端代码都是在计算机中完成渲染的,因此在对目标网页进行请求时,我们已经获得了目标网页前端的源代码。
因此,如果流行的查看方式被禁止了,我们还可以回归原始的文本查看方式。
将网页转化为文本文件的方式进行查看是必然可行的,浏览器的权限不可能比系统操作高。只有来硬的还是来软的区别。
来硬的,那就将这个网页直接保存在本地,然后使用文本编辑器查看。注意到右键被禁用,我们可以使用键盘快捷键ctrl + s解决。

来软的,那就通过浏览器层面的较底层协议实现,此时就可以将最前面加上view-source即可解决。
例如,将https://* 更改为view-source:https://*

不过,由于Google的奇葩更新,现在https://相关的协议会自动隐藏,这不利于我们技术人员的工作。
另外,view-source协议可以通过快捷键ctrl + u触发
方案二:化为相似解
注意到Web2的场景和Web1相比就是多了Hint中所言的JS前端限制,而我们也得知前端代码是先获取后渲染的,所以,我们能不能将JS代码删去以实现将Web2的场景向Web1的转化呢?
很明显,这样做有些奇怪,因为更新代码的前提就是得知这个网页的代码。但要是获取了网页源代码我不就直接去获取flag了吗?有点多此一举了。
不过我觉得可以试试。
之前下载的源代码中其实可以找到限制操作的JS代码

将其删除,再将其保存并使用浏览器打开,此时选取和右键功能都回来了。

恭喜,现在Web2被我们整回Web1的模样了,按F12也可以获取最后的flag

Web3
Hint: 没思路的时候抓个包看看,可能会有意外收获
进入靶机,发现这个网页中什么有价值的文本都没有,就只问了flag在哪里…
根据提示,我们需要抓个包。由于设备限制,目前电脑上没有装BurpSuite,因此我们使用浏览器自带的开发者控制台进行调试。
此时我们需要使用控制台的网络功能,先点开它,然后刷新页面重新开始录制网络活动。我们会注意到这一个简单的页面其实请求了多个文件,但css只是样式表,那些图片又只是靶场网站的图标,而且这又不是Misc。
因此,我们只需要关注html即可,但是内容正文的源代码还是没有显示额外的信息。那就只能检查网络协议了,果然,flag藏在了网络协议头里面。

Web4
Hint: 总有人把后台地址写在robots,帮黑阔大佬们引路。
注意到Hint中存在关键词robots,根据网络协议规范,网页根目录下的robots.txt是一种爬虫规范,旨在定义计算机自动程序对网站数据的获取规范。但是,人们肯定不会希望计算机程序自动识别到后台在哪里,就算认证方式足够安全,攻击者以爆破密码的方式天天DDoS不恶心吗?
所以有些SB就会将后台的目录写入到robots.txt。他们忘了一件事,robots.txt只防君子不防小人(等一下,我是不是在骂自己),这个文件是公开的,可以被请求的,也就是说甭管读取到这个文件的人进行了什么行为,它反正是可以被获取的,可以被查阅的。而且,txt文本文件格式人类想查看也不是什么难事。
方案一:遵从游戏规则
因此,我们可以直接访问robots.txt,看看写了些什么。它的正文如下:
User-agent: *
Disallow: /flagishere.txt
What can I say? 这都已经把flag的地址写在脸上了,直接访问即可得到flag
方案二:力大砖飞
在回顾这道题的解析过程时,发现这道题还是可以归纳为消费者向生产者的额外索要,我们之前遵循Hint,实现了一次较为绅士的掠夺,这回我们化身流氓,对目标网址进行无情的索要,也就是目录扫描。
此时就可以请出我们目录扫描工具dirsearch,对这个网页进行目录扫描,把它的底牌全部看透!
如果没有安装dirsearch,可以使用pip命令安装(注意前置依赖setuptools),至于Python新版本出现的对外部环境的增强限制,请自行创建Python虚拟环境:
1 | pip install dirsearch |
然后就可以对网页实行扫描并得到结果。很可惜的是,flagishere.txt不是一般情况下常见的文件,因此dirsearch默认是扫描不出来的。
Web5
Hint: phps源码泄露有时能帮上忙
进入靶机,又是什么都没有……这次想着去看协议头,发现也没有什么新的内容。
然后根据Hint,查看phps文件的内容,phps是php源代码的备份,获取这个文件和获取php文件没有什么区别。
然后就在其中发现了flag。
注意到phps这种文件本身会被浏览器直接下载下来,为了保证别被太多垃圾占满存储空间,还是多用用curl这类命令行工具。

Web6
Hint: 解压源码到当前目录,测试正常,收工。
Hint中指示的是一个非常正常的开发流程,理论上过程无错误,但在实际生产环境中这可就有些不严谨了。
应该说,这个过程的意思是,开发者首先将新一版的代码编写完毕,压缩成zip以节省空间,然后一通解压就完事了。可是,富含源码的压缩包开发者得记得从生产环境中删去。
如果不删去,那黑客们可不就得好好品鉴品鉴?
按照协议标准,目前的网页应用都是部署在www文件夹下面,它更加精细的定位是/var/www/
于是将进入靶机进行目录扫描,看一看有什么可用的事物。
然后我们就发现了一个文件,哇哦,这富含网络的名字,这饱含浓缩精华的后缀名,让人不想看它都难。
然后我们就可以在这个压缩包中找到源代码,找到flag

Web7&&Web8
Hint: 版本控制很重要,但不要部署到生产环境更重要。
这两个题目环境是Web6的延伸,意在不要将开发版本的源代码泄露到生产环境中。而版本控制必然会存储源代码的信息,不然怎么回滚?
这也就说明当目录扫描过程中出现了版本控制的文件夹,那可就得让黑客好好品鉴品鉴了。
Web7是Git,而Web8是SVN,这两个都是市面上主流的版本控制软件。而它们的版本控制数据分别保存在根目录下并做隐藏处理。
但很可惜的是,这样的存放是一个公开标准,难道目录扫描时我们攻击者会不知道吗?在对应的目录中获取到了flag
生产环境是面向所有已知的未知的消费者的,生产者就别干一些掩耳盗铃的事情了。
Web9
Hint: 发现网页有个错别字?赶紧在生产环境Vim改下,不好,死机了。
这个题目的hint也是在警告我们任何的修改都请在开发环境测试好了再推送到生产环境中。否则先不说系统留下的痕迹容易被攻击方利用,目标这样对生产环境的修改行为也是一种权限,级别还不低,属于是给攻击方扩大了进攻面。
而Vim的泄露更是重量级,Vim本身是一个Linux运维天天用的工具,其理念也和Linux万物皆文件的思路是一致的,因此Vim的任何行为都有可能会留下文件痕迹,例如这种紧急情况,出于对数据的保护,Vim会将使用者已经写入缓冲区的数据生成一个swp文件并保存在同一目录下。那可是缓冲区的数据,是生产者的一手数据,这攻击方闻着味都过来了。
因此在本题中直接访问根目录下的index.php.swp文件即可找到flag
不过说真的,现实场景中Linux运维通常是SSH远程连接服务器进行处理,Vim一般在自己的设备上。这个时候如果死机了,我觉得按照目前普遍99.99%的SLA,多少得和机房那边干一架,毕竟Vim本身的占用也不高。
Web10
Hint: cookie只是一块饼干,不能存放任何数据。
这个题目的hint警告我们不要将任何隐私信息放在cookie中,特别是不能明文存储任何cookie信息!
好了,现在进入靶机,呼出开发者控制台,在存储部分找到cookie,然后我们就找到了将大括号经过了URL编码的flag。

Web11
这个域名已经不能解析了,因此我们这里只记录方法。
注意到域名信息可以提供信息,而这个题目只提供了域名,因此我们需要使用DNS相关知识去找寻这个域名的信息。
那能使用到的技术就是nslookup反查了。
而且最好的一件事是,这种查询是公开的,谁都可以使用,因此我们可以直接要求域名反查时提供所有的信息。
1 | nslookup -query=any flag.ctfshow.com |
不过,由于题目信息中有指出txt记录在变化,所以我们也可以使用面向特定类型信息的查询。
1 | nslookup -type=txt flag.ctfshow.com |
Web12
Hint: 有时候网站上的公开信息,就是管理员常用密码。
所以,网站上公开了什么虽然是公开的,但是不希望被消费者看到的信息呢?
先查看robots.txt文件,发现这就是一个将后台地址写在robots.txt的大SB。进入后台,发现需要密码。
然后我们就可以猜测这个用户名和密码是什么了。注意到这个网页除了那些模板内容以外,下方有一串电话号码。
尝试以admin作为用户名,以这个电话号码为密码登录,成功了,然后就给了flag。
虽然但是,这种纯Guessing很没有技术含量,建议发配天天出这种题目的人去卢比扬卡挖土豆。
Web13
Hint: 技术文档里面不要出现敏感信息,部署到生产环境后及时修改默认密码。
这个地方可以类比到《头号玩家》中的经典片段,对头公司的CEO在“离开游戏”时发现自己被威胁了。但实际上这一切都是假的,主角团只是黑入了他的设备,让他错认为自己已经下线了。但很神奇的一件事就在于,他们是怎么黑入一个体量同样巨大的公司的内网的呢?
其实这只是因为CEO把账号密码全部写在了座椅旁边。这在这道题的环境中也是这样的。
进入这个靶机,发现下面的document可以下载,然后在这份文档里面找到了后台以及默认的用户名和密码,就这样,我们拿到了flag。
Web18
其他没写的题目基本上都退环境了。与其说是Web安全,倒不如说是社工,或者说就是目录扫描的事情。
Hint: 不要着急,休息,休息一会儿,玩101分就给你flag
靶机里是一个flappy bird小游戏,想玩够101分那妥妥的大神,但我们肯定不是这样玩的。
找到控制游戏逻辑的JavaScript代码,寻找里面的判断条件,发现101分时存在判定,要求我们去110.php中寻找flag
然后就获得了flag。
其他没写的题目
看着提示玩玩就行了,基本上你也很难在现实比赛题目中看到了,因为读环境这种容易和题目容器环境变量接触的行为容易产生非预期解。
- 标题: CTFshow-Web入门-信息搜集writeup
- 作者: Door
- 创建于 : 2025-04-03 18:22:18
- 更新于 : 2025-07-19 07:31:21
- 链接: https://chenshi.club/posts/a002dbfe.html
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。